
大規模または複雑なプロジェクトでは、要件定義書・仕様書・技術資料など、多くの文書が複数バージョンに分散し、矛盾・曖昧さ・欠落が頻繁に発生します。これらは誤解や手戻り、遅延の重大な原因となります。SpecLens は、これらの課題を根本から解決するために開発されたAIベースの プロジェクト要件分析アシスタント です。非構造化ドキュメントを整理し、矛盾を検出し、曖昧な点を明確化し、さらにナレッジベースとして即時検索・回答できる環境を構築します。
主な機能
-
ドキュメントの自動構造化(要件定義書・FRD・仕様書などを統合整理)
-
矛盾/欠落箇所の自動検出
-
曖昧表現のハイライト・明確化支援
-
AIによる自然言語Q&A(ナレッジベース化)
-
高速ベクトル検索による意味ベース検索
-
複数ドキュメントの統合一元管理
プロジェクト概要
SpecLensは、多様な形式のプロジェクト資料をAIが理解できる形に変換し、意味ベースで検索・回答できる「プロジェクトナレッジ基盤」を構築するシステムです。
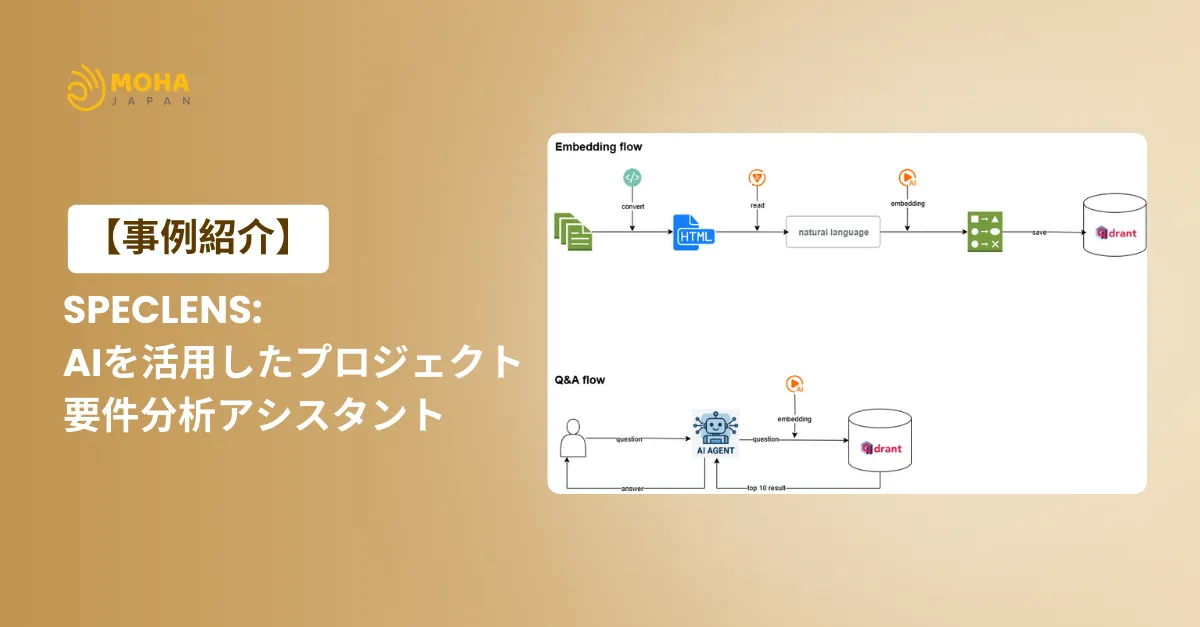
システムは以下の2つのコアフローで動作します:
1. 埋め込みフロー(Embedding Flow)
-
ドキュメントをHTMLへ変換
-
NLPで内容を解析し、重要語句・関係性を抽出
-
各セグメントをベクトル化
-
QdrantベクトルDBへ保存 → 高速検索を実現
2. Q&Aフロー(AI検索・回答)
-
ユーザーの質問をAIがベクトル化
-
類似ドキュメントを検索(上位10件)
-
AIが文脈に基づき、要約した最適な回答を生成
この結果、プロジェクトチームは複数の資料を読み漁ることなく、必要な情報を数秒で取得できるようになります。
主要情報
| 項目 | 詳細 |
|---|---|
| プロジェクト規模 | プロジェクト文書管理基盤、AI要件分析エンジン、ベクトル検索、Q&A UI |
| 期間 | 約 4〜5ヶ月 |
| チーム構成 | PM ×1、AIエンジニア ×2、フロントエンド ×1、バックエンド ×2、QA ×1 |
| 分野 | 要件分析、文書管理、自動化テック、NLP、LLM活用 |
| 使用技術スタック | Python、Node.js、NLP/LLM(OpenAI)、Qdrant、HTMLパーサ、Vector Embedding Pipeline、React UI、Docker、AWS |
影響と成果
1. 要件理解にかかる時間の大幅削減
-
数百ページの仕様書を読む必要がなくなり
情報検索が 30分 → 数秒 に短縮
2. 手戻り・誤解を事前に防止
-
矛盾や曖昧表現を自動検出し、
後工程でのトラブルを大幅に削減
3. ドキュメントの一元管理による生産性向上
-
チーム全体が同じ整合性のある情報源を利用
-
コミュニケーションコストを大幅に削減
4. プロジェクト品質の向上
-
初期段階での問題発見により、
成果物の品質と納期遵守率が向上
5. ナレッジベース化による属人性の解消
-
新メンバーでもすぐにプロジェクト理解が可能
-
組織全体での情報共有がスムーズに